







Тема 2.2. СУБД Microsoft SQL Server
2.2.1 Архитектура СУБД Microsoft SQL Server
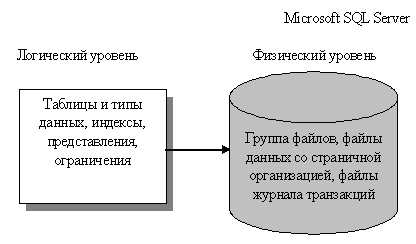
Рис.1. Архитектура базы данных в Microsoft SQL Server 2012
Рассмотрим логический уровень представления базы данных. Microsoft SQL Server 2012 представляет собой реляционную СУБД (данные представляются в виде таблиц). Таким образом, основной структурой модели данных этой СУБД являются таблицы.
В SQL Server в качестве языка работы с базами данных используется язык, который называется Transact-SQL. Этот язык является несколько измененным и расширенным вариантом языка SQL, определенного в международных стандартах. Еще говорят, что Transact-SQL является диалектом стандарта SQL. Операторы языка позволяют выполнять создание, изменение и удаление объектов базы данных и самой базы данных, создавать триггеры, хранимые процедуры, добавлять, изменять, удалять и отыскивать данные в таблицах базы данных.
Основной законченной единицей языка Transact-SQL является оператор (statement), который может состоять из нескольких предложений (clause). При написании операторов и предложений используются константы (литералы) и ключевые слова.
Файлы и файловые группы
На физическом уровне база данных в Microsoft SQL Server 2008 представляется набором файлов операционной системы. Данные и сведения журналов транзакций всегда размещаются в разных файлах. Отдельные файлы используются только одной базой данных. Файловые группы представляют собой именованные коллекции файлов и используются для упрощения размещения данных и выполнения задач администрирования, например резервного копирования и восстановления.
Базы данных SQL Server содержат файлы трех типов:
- Первичные файлы данных является отправной точкой базы данных. Он указывает на остальные файлы базы данных. В каждой базе данных имеется один первичный файл данных. Для имени первичного файла данных рекомендуется использовать расширение MDF.
- Вторичные файлы данных. К вторичным файлам данных относятся все файлы данных, за исключением первичного файла данных. Базы данных могут вообще не содержать вторичных файлов данных, или содержать один или несколько вторичных файлов данных. Для имени вторичного файла данных рекомендуется использовать расширение NDF.
- Файлы журналов содержат все сведения журналов, используемые для восстановления базы данных. В каждой базе данных должен быть по меньшей мере один файл журнала, но их может быть и больше. Для имен файлов журналов рекомендуется использовать расширение MDF, NDF и LDF. Однако эти расширения помогают пользователю идентифицировать различные виды файлов и правильно их использовать.
В SQL Server расположение всех файлов базы данных записывается в первичный файл базы данных и в специальную служебную структуру СУБД SQL Server, называемою базой данных master. В большинстве случаев при работе с базой данных компонент СУБД (SQL Server Database Engine) использует сведения о размещении файлов, хранимые в базе данных master. Однако в некоторых случаях (например, при восстановлении базы данных master из копии, при определенным образом проводимым присоединении базы данных) компонент Database Engine использует сведения о расположении файлов из первичного файла, чтобы инициализировать записи о расположении файлов в базе данных master.
Файлы SQL Server имеют два имени:
- logical_file_name — имя, используемое для ссылки на физический файл во всех инструкциях Transact-SQL. Логическое имя файладолжно соответствовать правилам для идентификаторов SQL Server и быть уникальным среди логических имен файлов в соответствующей базе данных.
- os_file_name — это имя физического файла, включая путь к каталогу. Оно должно соответствовать правилам для имен файлов операционной системы.
Изначально можно указать максимальный размер каждого файла. Если максимальный размер файла не указан, файлы SQL Server могут автоматически увеличиваться в размерах, превосходя первоначально заданные показатели, пока не займут все доступное место на диске. При определении файла пользователь может указывать требуемый шаг роста. Каждый раз при заполнении файла его размер увеличивается на указанный шаг роста. Если в файловой группе имеется несколько файлов, их автоматический рост начинается лишь по заполнении всех файлов. Затем файлы увеличиваются в размерах по кольцевому списку. Эта функция особенно полезна в случаях, когда SQL Server используется в качестве базы данных, внедренной в приложение, где пользователь не имеет удобного доступа к системному администратору. По мере необходимости пользователь может предоставить файлам возможность увеличиваться в размерах автоматически, тем самым снимая с администратора часть забот по наблюдению за свободным пространством базы данных и по распределению дополнительного пространства вручную.
Из объектов баз данных и файлов можно формировать файловые группы, используемые для решения задач распределения и административного управления. Файлы журналов не могут входить в состав файловых групп. Управление пространством журнала отделено от управления пространством данных. Файл не может входить в состав нескольких файловых групп. Таблицы, индексы и данные больших объектов могут быть ассоциированы с указанной файловой группой. В этом случае все их страницы будут размещены внутри файловой группы; либо таблицы и индексы могут быть секционированы. Данные секционированных таблиц и индексов разделяются на блоки, каждый из которых может быть помещен в отдельную файловую группу базы данных. В каждой базе данных одна файловая группа назначается файловой группой по умолчанию. Если при создании таблицы или индекса файловая группа не указывается, предполагается, что все страницы будут распределяться из файловой группы по умолчанию. В каждый момент времени лишь одна файловая группа может быть файловой группой по умолчанию.
Страницы и экстенты
Основной единицей хранилища данных и обмена информацией между внешней и оперативной памятью в SQL Server является страница. Место на диске, предоставляемое для размещения файла данных (MDF- или NDF-файл) в базе данных, логически разделяется на страницы с непрерывным перечислением от 0 до n. Дисковые операции ввода-вывода выполняются на уровне страницы. А именно, SQL Server считывает или записывает целые страницы данных. В SQL Server размер страницы составляет 8 КБ. Это значит, что в одном мегабайте базы данных SQL Server содержится 128 страниц. Каждая страница начинается с 96-байтового заголовка, который используется для хранения системных данных о странице. Эти данные включают номер страницы, тип страницы, объем свободного места на странице и идентификатор единицы распределения объекта, которому принадлежит страница.
Для эффективного управления памятью страницы объединяются в экстенты, которые являются основными единицами организации пространства.
Экстент — это коллекция, состоящая из восьми физически непрерывных страниц или 64 Кб; они используются для эффективного управления страницами. Все страницы хранятся в экстентах. Таким образом, в одном мегабайте базы данных SQL Server содержится 16 экстентов.
Чтобы сделать распределение места эффективным, SQL Server не выделяет целые экстенты для таблиц с небольшим объемом данных. SQL Server имеет два типа экстентов:
- Однородные экстенты принадлежат одному объекту (определенной таблице, индексу и т. д.); все восемь страниц могут быть использованы только этим владеющим объектом.
- Смешанные экстенты могут находиться в общем пользовании у не более восьми объектов. Каждая из восьми страниц в экстенте может находиться во владении разных объектов.
Новая таблица или индекс — это обычно страницы, выделенные из смешанных экстентов. При увеличении размера таблицы или индекса до восьми страниц эти таблица или индекс переходят на использование однородных экстентов для последовательных единиц распределения. При создании индекса для существующей таблицы, в которой содержится достаточно строк, чтобы сформировать восемь страниц в индексе, все единицы распределения для индекса находятся в однородных экстентах. Пример размещения объектов в смешанном и однородном экстентах приводится на рис.2.
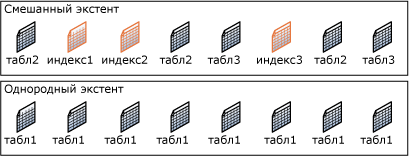
Рис.2. Размещение объектов в смешанном и однородном экстентах
Страницы файлов данных
Страницы файлов данных SQL Server нумеруются последовательно; первая страница файла получает нулевой номер (0). Каждый файл базы данных имеет уникальный цифровой идентификатор. Чтобы уникальным образом определить страницу базы данных, необходимо использовать как идентификатор файла, так и номер этой страницы. На рис.3. показаны номера страниц базы данных, содержащей первичный файл данных объемом в 4 МБ и вторичный файл данных объемом в 1 МБ.
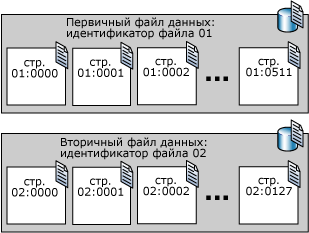
Рис.3. Пример нумерации страниц файлов базы данных
Первая страница каждого файла (страница с номером 0) — это страница заголовка файла; она содержит сведения об атрибутах данного файла. Страницы с номерами 1,2,3 будут описаны ниже.
Организация таблиц и индексов
Таблицы и индексы хранятся в виде коллекции страниц размером 8 КБ.
Страницы таблиц и индексов содержатся в одной или нескольких секциях. Секция — это пользовательская единица организации данных. По умолчанию таблица или индекс имеет единственную секцию, которая содержит все страницы таблицы или индекса. Секция располагается в одной файловой группе. Таблица или индекс, имеющие одну секцию, эквивалентны организационной структуре таблиц и индексов предыдущих версий SQL Server.
Если таблица или индекс используют несколько секций, данные секционируются горизонтально, так что группы строк сопоставляются отдельным секциям, основываясь на указанном столбце. Секции могут храниться в одной или нескольких файловых группах в базе данных. Таблица или индекс рассматриваются как единая логическая сущность при выполнении над данными запросов или обновлений. Секция состоит из фрагментов одного или нескольких файлов. Данные внутри фрагмента файла представляются в виде кучи (строки данных хранятся без определенного порядка – последовательное размещение) или сбалансированного дерева. Фрагмент файла может иметь один из трех видов: данные с типами небольших размеров (данные IN_ROW_DATA), данные с типами больших размеров (LOB_DATA), данные переменной длины (переполнение строки ROW_OVERFLOW_DATA).
В каждой секции кучи или индекса содержится по крайней мере одна единица распределения IN_ROW_DATA. Кроме того, в зависимости от схемы кучи или индекса, там могут содержаться единицы распределения LOB_DATA или ROW_OVERFLOW_DATA.
Следующая иллюстрация показывает организацию таблицы (рис.4).
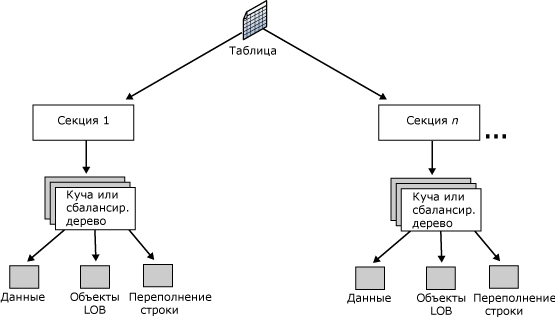
Рис.4. Физическая структура таблицы в базе данных SQL Server
Каждая секция содержит строки данных либо в куче, либо в структуре кластеризованного индекса. Кластеризованный индексреализуется в виде структуры индекса сбалансированного дерева, которая поддерживает быстрый поиск строк по их ключевым значениям. Страницы в каждом уровне индекса, включая страницы данных на конечном уровне, связаны в двунаправленный список. Однако перемещение из одного уровня на другой выполняется при помощи ключевых значений.
Куча — это последовательность строк таблицы, которые не имеют кластеризованного индекса. Строки данных хранятся без определенного порядка, и какой-либо порядок в последовательности страниц данных отсутствует. Страницы данных не связаны в связный список.
Управление работой с экстентами и свободным местом
Структуры данных SQL Server, управляющие использованием экстента и отслеживанием свободного места, обладают относительно простой структурой. Сведения о свободном месте плотно упакованы, поэтому эти данные содержат относительно небольшое количество страниц. Это приводит к увеличению скорости из-за уменьшения необходимых операций чтения диска для получения сведений о размещении. Также увеличивается вероятность того, что страницы размещения будут оставаться в памяти и повторных операций чтения не потребуется. Большая часть сведений о размещении не связана по цепочке друг с другом. Это упрощает управление сведениями о размещении. Каждое действие по размещению или освобождению страницы может выполняться быстро. Это сокращает конфликты между одновременными задачами использования и освобождения страниц.
SQL Server использует два типа карт для записи сведений об использовании экстентов:
· Глобальная карта распределения (GAM) На GAM-страницах записано, какие экстенты были задействованы. В каждой карте GAM содержатся сведения об использовании 64 000 экстентов или о размещении почти 4 ГБ данных. В карте GAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент свободен; если бит равен 0, то экстент задействован.
· Общая глобальная карта распределения (SGAM) На SGAM-страницах записано, какие экстенты в текущий момент используются в качестве смешанных экстентов и имеют как минимум одну неиспользуемую страницу. В каждой карте SGAM содержится сведения об использовании 64 000 экстентов или о размещении почти 4 ГБ данных. В карте SGAM приходится по одному биту на каждый экстент в покрываемом им интервале. Если бит равен 1, то экстент используется как смешанный экстент и имеет свободную страницу. Если бит равен 0, то экстент не используется как смешанный экстент, или он является смешанным экстентом, но все его страницы используются.
Отслеживание свободного места
На страницы PFS (Page Free Space) записывается состояние размещения каждой страницы, информация о том, была ли отдельная страница использована или нет, а также количество свободного места на каждой странице. В PFS на каждую страницу приходится по одному байту, хранящему информацию о том, была ли страница использована или нет, а если была — то пустая она, или ее заполнение находится в промежутке от 1 до 50 процентов, от 51 до 80 процентов, от 81 до 95 процентов или от 96 до 100 процентов.
После размещения объекта в экстенте компонент Database Engine использует PFS-страницы для записи информации о том, какие страницы в экстенте использованы, а какие свободны. Эти сведения используются компонентом Database Engine при выборе новой страницы для размещения объектов. Количеством свободного места на странице можно управлять только в случае кучи и страниц с типами данных PFS-страница является первой страницей после страницы заголовка файла в файле данных (страница номер 1). Потом следует GAM-страница (страница номер 2), а затем SGAM-страница (страница номер 3). После первой PFS-страницы находится PFS-страница размером примерно 8 000 страниц. После первой GAM-страницы на странице 2 находится другая GAM-страница с 64 000 экстентов и другая SGAM-страница с 64 000 экстентов находится после первой SGAM-страницы на странице номер 3.
На рис.5 показана последовательность страниц, используемая компонентом Database Engine, для размещения и управления экстентами.
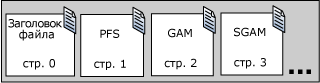
Рис.5. Страницы файла, используемые для размещения и управления экстентами

